Inline tags
Inline tags represent:
XML content that can be part of the source segment. XML content can represent items such as page formatting on a web application such as bold and italic.
Note
They are shown as {1}represented as such {1} in XTM Workbench (CAT). The content of the Inline tag is shown by clicking on it either in the source segment or target segment.
The meaning (e.g newline, bold, etc.) of the inline can be shown in Workbench for the MS Word file format. This is set in (Configuration->Filter Templates->display hints about inline tags)
HTML tags such as HTML page elements.
Note
HTML tags for all source segments can be shown in XTM Workbench as inline tags by configuring Filter Templates (Configuration->Filter Templates). This only applies to MS Office or G-Suite applications.
Filter Templates can also be created for any other file format. Please contact your XTM point of contact for more details.
By default, any URL or hyperlink in a segment is treated as translatable text and not as an untranslateable inline tag. This setting can be changed.
The inline tags in the source text need to be placed in the translated target text. However, you can modify the order of inline tags provided that the sequence of opening and closing tags is correct.
Tip
By default, inline tags are automatically inserted into the Target Segment. This can be deactivated in XTM Workbench under Allow Auto-insert inline tags .
If deactivated manual insertion is added from the context menu in XTM Workbench. The list of missing inline tags is available in a popup.
The following table indicates how inline tags are displayed in XTM Workbench (CAT) for the linguists:
Table 10. Inline Tag Description and XTM Workbench ReferenceINLINE
DESCRIPTION
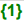
Represents text formatting, e.g. bold, italics, etc.; an opening and closing tag are required: {1}content{1}

Represents untranslatable, anonymized elements, or HTML elements; they appear as single tags.
Note
The anonymization feature is based on Named Entity Recognition (NER) and it attempts to identify confidential personal data by converting it to inline tags. This works for Dutch,Danish, English,French,German,Italian,Portuguese,Spanish,Swedish.

Represents atypical spaces or special characters; they appear as single tags.